Aerospike Database es un sistema de gestión de bases de datos NoSQL (Not Only SQL) que está diseñado para ser altamente eficiente y escalable en entornos distribuidos y en tiempo real. Es conocido por su rendimiento rápido, baja latencia y alta disponibilidad, lo que lo hace adecuado para aplicaciones que requieren respuestas rápidas y consistentes
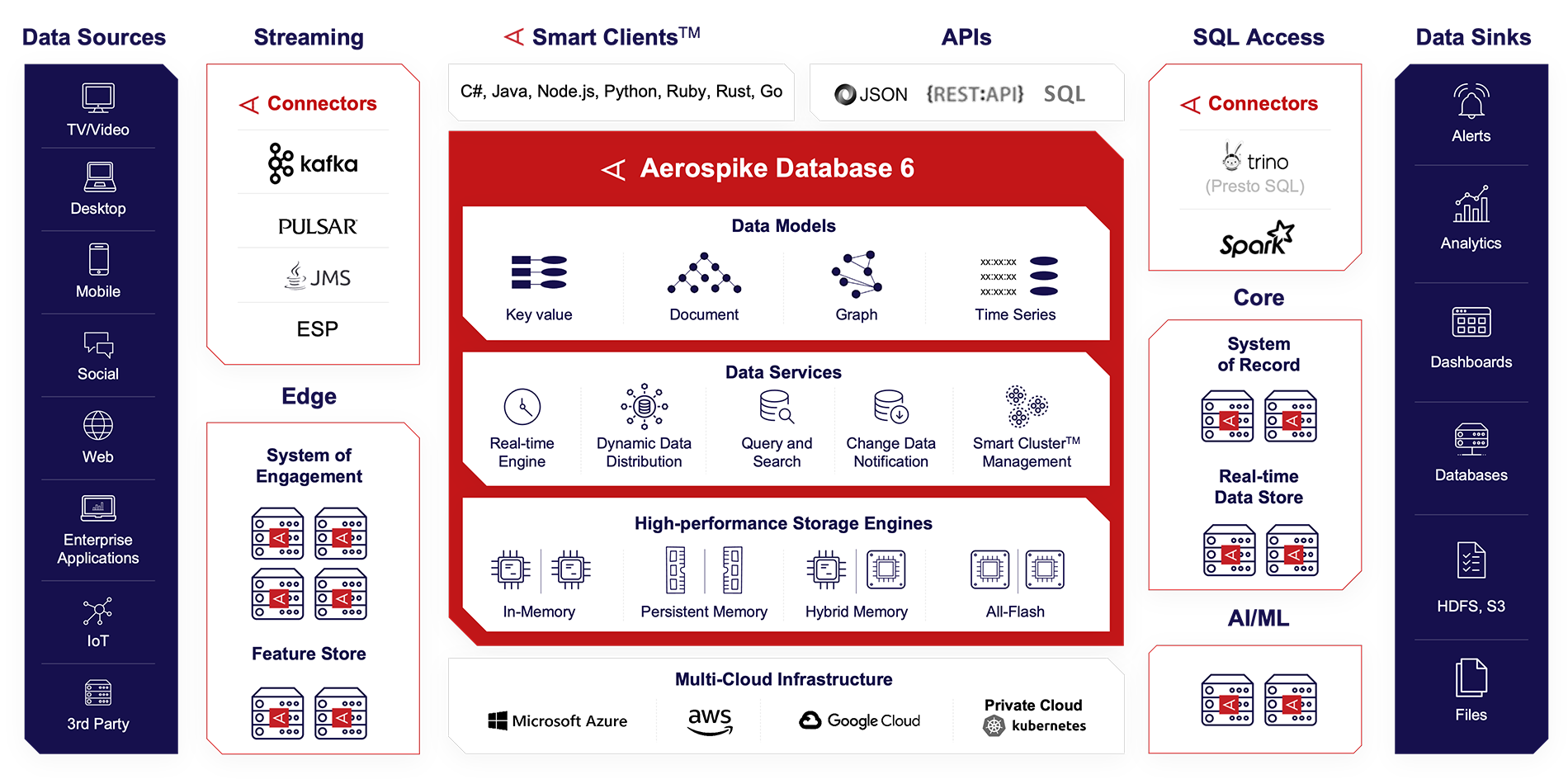
Aerospike Database se modela bajo la arquitectura shared-nothing y se escribe en C. Funciona en tres capas: una capa de almacenamiento de datos, una capa de distribución autogestionada y una capa de cliente consciente del clúster.
Aerospike utiliza una arquitectura de memoria híbrida: los índices de la base de datos se almacenan completamente en la memoria principal de acceso aleatorio, mientras que los datos se almacenan en un dispositivo persistente utilizando la capa de datos. La capa de datos almacena los datos en una unidad de estado sólido, NVMe o memoria persistente. La lectura de los datos se realiza mediante un acceso directo a la posición del registro en el disco utilizando un puntero directo desde el índice primario, y las escrituras de datos se optimizan mediante escrituras en grandes bloques para reducir la latencia. Esta arquitectura permite obtener todos los registros del dispositivo persistente y anula el uso de la caché de datos. Aerospike también ofrece la posibilidad de almacenar los datos completamente en RAM, actuando así como una base de datos en memoria. En ese caso, los datos se persistirían en SSD, NVMe, PMEM o medios rotativos tradicionales.
Aerospike proporciona transacciones ACID de registro único. La capa de distribución se encarga de replicar los datos entre nodos para garantizar las propiedades de durabilidad y consistencia inmediata de la transacción. Esto permite que la base de datos permanezca operativa incluso cuando un nodo de servidor individual falla o se retira manualmente del clúster. Desde la versión 4.0 (2018), Aerospike Database se puede configurar como Disponible y tolerante a particiones (AP) o Consistente y tolerante a particiones (CP) bajo el teorema CAP.
Arquitectura de Alto Rendimiento: Aerospike está diseñado para manejar grandes volúmenes de datos y operaciones de lectura y escritura con baja latencia. Utiliza una arquitectura híbrida en memoria y en disco para lograr un rendimiento óptimo.
Escalabilidad Horizontal: Es altamente escalable y puede distribuirse de manera eficiente en clústeres de nodos para manejar cargas de trabajo crecientes. Esto permite escalar horizontalmente añadiendo más nodos al clúster.
Modelo de Datos Simple: Aerospike admite un modelo de datos simple basado en pares clave-valor. Cada registro en la base de datos tiene una clave única y un valor asociado, que puede ser cualquier tipo de datos, como cadenas, números o estructuras complejas.
Consistencia y Tolerancia a Fallos: Ofrece configuraciones flexibles para equilibrar la consistencia, la disponibilidad y la tolerancia a fallos, permitiendo a los desarrolladores ajustar según los requisitos específicos de sus aplicaciones.
Operaciones en Tiempo Real: Está diseñado para admitir aplicaciones en tiempo real, como sistemas de recomendación, análisis de registros y personalización de contenido, donde la baja latencia y el rendimiento son críticos.
Soporte para Transacciones ACID: Aerospike proporciona soporte para transacciones ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad) en operaciones individuales, lo que garantiza la integridad y la consistencia de los datos.
APIs y Soporte Multi-Modelo: Además del modelo de datos clave-valor, Aerospike también admite consultas secundarias y consultas de índices para ofrecer flexibilidad en el acceso a los datos.
La capa cliente cluster-aware se utiliza para rastrear la configuración del cluster en la base de datos, y gestiona las comunicaciones directas del cliente con todos los nodos del cluster. La agrupación en clusters se realiza utilizando heartbeats y el algoritmo de protocolo de cotilleo basado en Paxos.
El software emplea dos subprogramas llamados Defragmenter y Evictor Defragmenter elimina bloques de datos que han sido borrados, y Evictor libera espacio RAM eliminando referencias a registros caducados.
¿Que es el Cap Theorem?
El teorema CAP, propuesto por el científico de la computación Eric Brewer en 2000, es un principio teórico que describe las limitaciones fundamentales de los sistemas distribuidos. El acrónimo «CAP» se refiere a tres propiedades clave que un sistema distribuido no puede lograr simultáneamente en presencia de fallos de red:
Consistencia (Consistency): Todos los nodos en el sistema ven los mismos datos al mismo tiempo. En otras palabras, la consistencia garantiza que cualquier lectura en el sistema devuelva la información más reciente y actualizada.
Disponibilidad (Availability): Cada solicitud a un nodo del sistema recibe una respuesta, sin importar si el nodo está experimentando fallos o dificultades en la red. La disponibilidad implica que el sistema siempre está disponible para responder a las solicitudes, incluso en condiciones de fallos.
Tolerancia a particiones (Partition Tolerance): El sistema continúa funcionando a pesar de la pérdida de mensajes o la partición de la red. La tolerancia a particiones significa que el sistema sigue siendo operativo incluso cuando algunos nodos no pueden comunicarse entre sí debido a fallos en la red.
El teorema CAP establece que en un sistema distribuido, es imposible garantizar simultáneamente consistencia, disponibilidad y tolerancia a particiones en todos los nodos. En lugar de eso, un sistema distribuido puede elegir proporcionar dos de las tres propiedades al mismo tiempo.
Esto lleva a tres posibles configuraciones:
CA (Consistency y Availability): Prioriza la consistencia y la disponibilidad a expensas de la tolerancia a particiones. En este caso, el sistema se comportará de manera consistente y siempre estará disponible, pero podría experimentar problemas si hay fallos en la red.
CP (Consistency y Partition Tolerance): Prioriza la consistencia y la tolerancia a particiones a expensas de la disponibilidad. En este caso, el sistema garantizará la consistencia y seguirá siendo operativo incluso si hay particiones en la red, pero puede experimentar períodos de indisponibilidad.
AP (Availability y Partition Tolerance): Prioriza la disponibilidad y la tolerancia a particiones a expensas de la consistencia. En este caso, el sistema siempre estará disponible y seguirá operando incluso en presencia de particiones en la red, pero puede haber divergencias en los datos entre los nodos.
La elección entre estas configuraciones depende de los requisitos específicos de cada aplicación y de las prioridades del sistema distribuido en términos de consistencia, disponibilidad y tolerancia a particiones.