A veces en BI todo tiene que pasar por procesos ETL. Aunque casi todos los tool permiten agregar datos de forma lineal y sencilla, muchas veces es necesario construir data marts para analizar parte del negocio o hacer análisis cruzadas con datos externos (Big Data). Uno de los puntos cruciales dentro de un proyecto BI es la normalización de los datos y su forma de acceder a ellos. El usuario de negocio y el analista BI a veces tienen que rendirse delante de respuestas sin datos a preguntas muy obvias y esto es frustrante.
Técnicamente Querona es un concentrador de datos de autoservicio que ayuda a construir una capa de acceso a datos central, consulta todas las fuentes de datos desde un lugar y acelera las consultas utilizando Apache Spark. Debajo del capó, Querona simula el protocolo SQL Server que lo hace compatible con cualquier herramienta de Business Intelligence en el mercado.
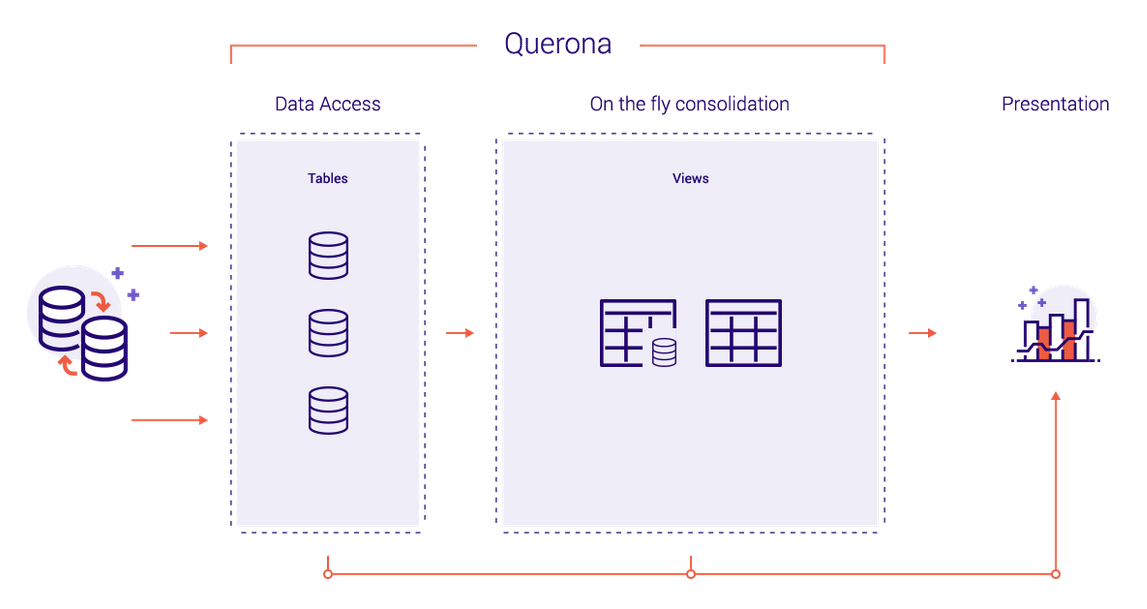 Querona fue diseñado para la simplicidad de uso. El usuario puede conectar fuentes de datos que serán visibles como una base de datos virtualizada de SQL Server y consultadas en tiempo real.
Querona fue diseñado para la simplicidad de uso. El usuario puede conectar fuentes de datos que serán visibles como una base de datos virtualizada de SQL Server y consultadas en tiempo real.
En el paso siguiente, los usuarios pueden aplicar seguridad o decidir almacenar datos en un motor SQL de su elección. La característica única es la plena integración con Apache Spark. Con un solo clic, los datos se cargan en Spark y se ponen a disposición para análisis adicionales o simplemente para construir un almacén de datos lógico rápido y barato (Spark es de código abierto).
Ahora, los cuadros de mando de Targit, Tableau, QlikView o Power BI pueden funcionar más rápido. El tiempo de solución para la creación de informes y cuadros de mando se acorta, a los analistas de datos y a los científicos de datos se les da más poder.
Spark… ¿porque no?
Apache Spark es un sistema de computación cluster. Proporciona APIs de alto nivel en Java, Scala, Python y R, y un motor optimizado que soporta gráficos de ejecución general. También soporta un rico conjunto de herramientas de alto nivel, como Spark SQL para SQL y procesamiento de datos estructurado, MLlib para el aprendizaje automático, GraphX para procesamiento de gráficos y Spark Streaming.
Adios ETL
Las capas de un almacén de datos lógico en Querona son sólo puntos de vista. No es necesario diseñar procesos ETL, basta con decidir qué vistas se almacenan en caché, cuándo y dónde.
La interfaz de autoservicio de Querona facilita la conexión de nuevas fuentes de datos, la exploración de datos y la preparación de martes de datos para informes.
Puede decidir lo que debe almacenarse en caché o almacenar en EDW más tarde.
Un almacén de datos en la nube puede seleccionarse rápidamente como una base de datos de almacenamiento en caché. La carga de datos para una vista seleccionada es sólo un clic. El almacén en la nube está protegido por la autenticación integrada de Windows, derechos de acceso y enmascaramiento de datos de Querona.
La capa de Querona Data Virtualization es un único punto de acceso a todas las fuentes de datos. La autenticación, la autorización basada en funciones, los derechos de acceso multinivel y el enmascaramiento de datos se aplican en todas las fuentes de datos.
Las consultas lentas se pueden acelerar mediante el almacenamiento en caché, el procesamiento en memoria en Apache Spark o el replanteo de consultas a un motor de ejecución diferente. La reescritura de la consulta elegirá automáticamente el mejor preagregado.
Querona soporta múltiples motores de ejecución SQL al mismo tiempo. Simplemente puede decidir qué datos se almacenan en caché en qué base de datos de almacenamiento en caché y qué se almacena en Hadoop.
Como funciona?
En una primera fase se pueden importar todas las fuentes de datos. Las decisiones empresariales dependen de los datos de múltiples fuentes de datos. Basta con importar todas las bases de datos, CRM o sistemas ERP en una base de datos virtual. Sólo unos pocos clics, ningún ETL involucrado. Una vez terminado este proceso se tiene acceso a todos los datos desde un único concentrador de datos.
Muchas veces la analítica en tiempo real es crucial para la toma de decisiones, pero es difícil de lograr para múltiples fuentes de datos. Querona permite el acceso directo a cualquier dato utilizando sólo SQL estándar. Todas las Aplicaciones en nube, bases de datos, CRMs, ERP unificados y todo consolidado, el sueño de cualquier director de sistema.
¿Alguna vez has tenido que unir datos ERP y CRM? Esto quería decir construir cubos OLAP hacer ETL con todo lo que conlleva en termino de esfuerzo y tiempo. Ahora con Querona simplemente se construye una capa de consolidación de datos utilizando una sencilla interfaz de autoservicio para consolidarlo todo en tiempo real.
Hoy en día los volúmenes de datos están aumentando, los cuadros de mando se están ralentizando. La solución a veces es aparcar viejos ejercicios en otros DW para que las consultas sean más rapidas. Necesitas un motor SQL Engine con gran capacidad de datos, pero la carga de datos en Hadoop es una tarea compleja. Querona ha reemplazado a ETL con un solo clic para almacenar datos en Hadoop. La descarga de la ejecución de consultas y la carga de datos en una nube o motores locales como Apache Spark SQL no son un reto son una realidad. Apache Spark ejecuta programas hasta 100 veces más rápido que Hadoop ya que cuenta con un avanzado motor de ejecución de DAG que soporta el flujo de datos acíclicos y la computación en memoria.
¿Y la seguridad?
Nunca es fácil hacer cumplir el acceso seguro a todas las fuentes de datos. Asegurar un almacén de datos en la nube Data Lake Hadoop es un reto aún mayor. Querona es el centro de datos para todas las fuentes de datos. Se pueden aplicar fácilmente derechos de acceso a cualquier nivel y a cualquier dato. Con el inicio de sesión único con NTLM y Kerberos, seguridad de filas y columnas y enmascaramiento dinámico de datos, lo tiene todo en un solo lugar.
El acceso a datos en tiempo real depende de la configuración del controlador en los equipos cliente. Pero Querona emula el protocolo SQL Server, lo que significa que simplemente usa cualquier herramienta cliente que soporte SQL Server. Imagine que cree una hoja de cálculo de Excel conectada a Querona. Esto le permite distribuir el archivo en toda la empresa, permitiendo que cualquier usuario, limitado sólo por sus derechos de acceso, consulte este nuevo origen de datos.
Querona es una base de datos virtual que permite pasar a través de acceso a todas las fuentes de datos corporativos desde un lugar – ahora la presentación de informes es más simple. Hay un lugar para encontrar todas las fuentes de datos. Querona acepta SQL estándar (compatible con SQL Server) y traduce consultas para ejecutarlas en otras bases de datos. Puede ejecutar SQL completo en cualquier fuente de datos, no importa si es SQL Server, Oracle o una aplicación en la nube como SalesForce o Marketo. La exploración de datos, la preparación de datos y la creación de prototipos de informes están disponibles al instante.
Sobre Querona
Querona se especializa en almacenamiento lógico de datos, virtualización de datos y análisis. Presentan una visión innovadora sobre Business Intelligence (BI) y ofrecen herramientas para que las empresas tengan éxito en un entorno de ritmo rápido.
Su compromiso con la innovación resultó en el desarrollo de la plataforma de software QueronaTM que hace que el análisis de BI y Big Data funcione más fácil y rápidamente.

Querona Ltd.
The Black Church, St, Mary’s Place
Dublin D07 P4AX
Ireland
CEE Office
Kwitnącego Sadu 8
02-202 Warszawa
Poland
info@querona.com